
Definition of End-to-End Test Automation Success
Measuring test automation attempts objectively. Only after knowing and admitting what went wrong, people can learn and succeed.


Test Automation failures are everywhere.

Here are comments I heard personally while working in three large IT divisions (each with 200+ staff, and numerous agile coaches/scrum masters) in my city.
“This company had four attempts of test automation. Every single time, in the beginning, people were excited. Soon nobody is interested” — a veteran tester
“For the last 12 years in this company, test automation attempts all failed. I admit I don’t know about test automation. I welcome anyone’s suggestions.” — a test lead said in a meeting after the company’s new $3 million test automation attempt failed.
“Maintenance of these Gherkin automated tests cost three times of our development effort (coding).” — a manager (and test automation was dumped later, but the principal software engineer who was responsible stayed)
Ironically, the individual engineers (or even test managers) claimed they did successful test automation personally. Based on their Résumés, we can conclude that most projects did automation well, “real Agile/DevOps”. I would say, not all of them are liars, just they assessed test automation wrongly and differently.
For readers who disagree with >99% failure (in the heading image of this article) for UI test automation attempts, check out the comment below. Compared to 99.75% (0.5% x 0.5%) failures indicated for Microsoft engineers, my >99% is quite conservative.
“95% of the time, 95% of test engineers will write bad GUI automation just because it’s a very difficult thing to do correctly”.
- the interview from Microsoft Test Guru Alan Page (2015)
Achieving UI test automation success is possible, but first, engineers must be clear about the goal. In this article, I will share my definition of Functional (End-to-End) Test Automation Success, in simple and objective measurements.
Test Count: 200+ user-story level UI tests
Overall Pass Rate (average individually): 95+%
(success runs, of course, 100%)Overall Duration (executing all tests): <1 hour
Running Frequency: all tests multiple times a day
(if there were changes)Recent green build: today or yesterday
All of the above contribute to the ultimate goal: daily production releases.
Table of Contents:
· The real challenge of test automation is Maintenance, not creation
· Test Count (coverage)
∘ Why 200 test cases?
· Overall Pass Rate (quality)
∘ Why 95+%?
· Duration (execution of all tests)
· Running Frequency
· Recent green buildI know some engineers don’t like the above specific and objective criteria. Sorry, but test automation is all about being specific (checks) and objective (binary, 0 or 1). If you are not comfortable with these, you probably shouldn’t do test automation.
The real challenge of test automation is Maintenance, not test creation
Developing a handful of automated tests is easy. Back in the last century, people could use recorders in WinRunner or QuickTest Pro to create ‘working’ automated tests. I have seen a number of demos like that. The audience who haven’t seen test automation before would often comment: “Cool!”.
However, this is an individual (in terms of both test cases and staff) level and has little meaning to the project. The real challenge of test automation is maintenance, not test creation. This is decided by the nature of software development and automated testing: application changes frequently; one simple change might affect many parts of the software; test automation needs a 100% pass.
That’s why for most test automation attempts, after the initial excitement, people found tests started failing. Getting a green build (passing all tests) seems impossible. Then they quietly gave it up. Managers would think “we always do manual testing anyway”. Until another ‘ambitious’ CIO joined the company, who might start another round of test automation attempts.
Test Count (coverage)
Test count is the total number of E2E (UI) automated test cases (user-story level) in the regression suite.
Target: 200 user story test cases
Below are the test counts for my two apps (shown in the BuildWise CT server):
WhenWise (web app): 551
Test Automation frameworks: raw Selenium WebDriver with RSpec
Testing tool: TestWise

TestWise (desktop app): 307
Test Automation frameworks: raw Appium +WinAppDriver with RSpec
Testing tool: TestWise

Why 200 test cases?
Based on my experience, 50 and 200 are two bottlenecks in implementing E2E UI test automation (user story level). If the team passes these thresholds, their ability will reach a new level.
For a typical business application, to make test automation very useful, the test scripts shall cover at least 80% of core business features. I know many companies define user acceptance scenarios which are often quite big. In a financial company I once worked for, 1200 (regression tests) is the number as it was repeatedly mentioned in the meetings. I remember talking to the test lead about it: “Forget about 1200. Despite talking about the target, there is nothing to show. Instead, focus on developing a couple per day and make sure all tests are valid every day”.
Anyway, 200-tests is a good target to aim for. If you are interested in the grading and how do you compare against other companies, check out “AgileWay Continuous Testing Grading”.
Overall Pass Rate (quality)
Definition: the percentage of successful individual test executions during a long period,
Target: 95+%
WhenWise (web app): 98.0%


ClinicWise (web app): 97.9%


TestWise (desktop app): 98.2%
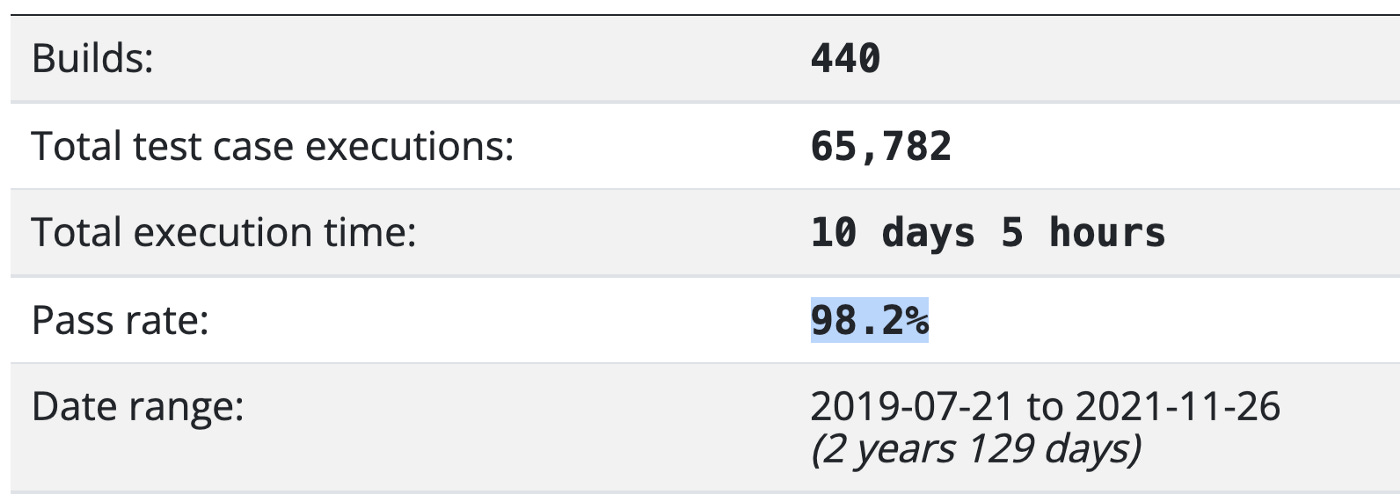
Why 95+%?
During the life of an automated test, the first execution pass is just a start. It will take more effort to stabilise the tests, such as
will there be side effects (such as changing the app state) that might not run successfully the next time?
will the test data be reusable?
will it run OK on different dates (e.g. 29/02) and times (time zone issue)?
will the test scripts be flexible with application changes?
for example, must not use GUID as the identifier to locate a web control
Check out this article Working Automated Test ≠ Good Reliable Test for a case study of my daughter’s automated tests written for an interview.
To qualify for a regression test, which will be run often, an automated test execution reliability must be high. Otherwise, it will just cause frustrations, such as no single green build for nine months.
Why not 100%? It is impossible, as the average pass rate. For example, a wrong deployment configuration or a failure of infrastructure might cause a large number of test failures. From my experience, 95% is the minimum threshold, after that, a capable Continuous Testing server (not CI servers) would help. See below for more.
Duration (execution of all tests)
Target: 1 hour
Once a manager came to me to help her assess test automation. After she mentioned it would run 14 hours in Jenkins. I told her there was no need for assessment as it had already failed. Why? It took too long. How would a team address the test failures? It usually takes a few tries to resolve all the test failures. 14 hours for a regression run, it is simply impossible for the test automation to succeed. Don’t forget, in the meantime, application changes.
The execution time for my own apps (see the screenshot above):
WhenWise (web), 548 Selenium tests
39 minutes with 7 BuildWise agents
if running on a single machine, 3.5 hours, a saving of 82%.TestWise (desktop), 307 Appium tests
57 minutes with 2 BuildWise agents
if running on a single machine, 1.5 hours.
End-to-End automated tests take a much longer time to run, compared to unit and API tests. This makes implementing automated UI tests more challenging. However, because of its great benefits, many software projects/companies attempted it, though most failed. One of the reasons that they never had experience in executing a large test suite is that it takes hours (if run one by one sequentially).
Feedback is important in test automation. To reduce feedback time, there are several practices. I have mentioned them in my book “Practical Continuous Testing: make Agile/DevOps real”, such as:
Distributing tests to multiple build agents to run them in parallel
don’t try to alter the test scripts (some JS test frameworks do), it is the CT server’s responsibility.Dynamic ordering
CT server runs most recently failed tests first. While this does not reduce the overall feedback, it will provide quick feedback to your desired tests.
A common problem with parallel execution is that software projects use the wrong tools. For example, Jenkins and Bamboo are CI servers. They are OK for running unit tests, but not good for executing UI tests (unless the CI server has built-in CT capabilities), which is better to run in CT servers, such as BuildWise or Facebook’s Sandcastle.
I recommend a Great CI/DevOps Presentation: “Continuous Integration at Facebook”.
Running Frequency
Target: multiple times per day
As we know, E2E automated tests are fragile, compared to API tests. However, if a software team have already embarked on this journey, this cannot be an excuse for failures anymore. There is a solution: executing ALL tests frequently, multiple times a day. Only in this way, we can detect the regression issues earlier. The earlier we find the issue, the cheaper and easier we resolve it.
Take WhenWise for example,
1270 builds (in BuildWise CT server) over three years and 295 days,
that is an average of 0.91 builds (running the whole automated regression suite) per day (including weekends and holidays)

333,385 test case executions
averagely, 239 test executions per day.
To give you a comparison, a test manager at a government project told me: the estimated test case execution for the test team (9 manual testers) is 3,000 per month.
Please note that WhenWise is just one of several apps (all with commercial customers) I developed and maintained in my spare time. As you can imagine, in a real Agile/DevOps team, these numbers will be much higher.
Recent green build
Target: today or yesterday
“Why do I have to get a green build or understand the causes for failures by the end of the day? Because it will be harder tomorrow, if I don’t.” — Zhimin Zhan
To achieve this requires:
the executives really understand software development (many don’t)
technical excellence in the team
discipline
passion
It might sound hard, but the rewards are great: the team will have the capability like Facebook: Release twice a day.
“Facebook is released twice a day, and keeping up this pace is at the heart of our culture. With this release pace, automated testing with Selenium is crucial to making sure everything works before being released.” — DAMIEN SERENI, Engineering Director at Facebook, at Selenium 2013 conference.
and LinkedIn as well.
“It was Scott and his team of programmers who completely overhauled how LinkedIn develops and ships new updates to its website and apps, taking a system that required a full month to release new features and turning it into one that pushes out updates multiple times per day.”
— The Software Revolution Behind LinkedIn’s Gushing Profits, Wired, 2013
Expecting a smooth run of a big suite of automated UI tests passively is not practical. Take the WhenWise test suite as an example, there are over 28,000 test steps (such as clicking a button, entering text, performing a check, …). A green build means each of these 28,488 steps passes.
+------------+---------+---------+---------+--------+
| TEST | LINES | SUITES | CASES | LOC |
| | 26032 | 334 | 557 | 20405 |
+------------+---------+---------+---------+--------+
| PAGE | LINES | CLASSES | METHODS | LOC |
| | 9863 | 181 | 1621 | 7449 |
+------------+---------+---------+---------+--------+
| HELPER | LINES | COUNT | METHODS | LOC |
| | 819 | 5 | 61 | 634 |
+------------+---------+---------+---------+--------+
| TOTAL | 36714 | | | 28488 |
+------------+---------+---------+---------+--------+One important feature of CT servers is Auto-Retry (where traditional CI servers such as Jenkins lacks). That is, if an automated UI test failed on one build agent, the CT server would allocate it to another build agent to try again. This has greatly reduced the false alarms (test execution failures not due to the application or test scripts).
Below is a run of the WhenWise test suite in the BuildWise CT server. As you can see, it is a green build with detected 14 false alarms. This also shows even with a high overall test pass rate of 98%, without the CT server’s retry (and other features) it is still hard to get a green build for a larger test suite (in this case, 548 tests).

I have been releasing all my apps daily (if changes were made) since 2012 (and before that, I did for some projects as a contractor). After getting a green build on the BuildWise CT server, I pushed the new version to production immediately.
I cannot think of developing software any other way.
“We have been told many times that this is a very difficult discipline to put in place, but once it is working, no one would ever think of going back to the old way of doing things.”
- Implementing Lean Software Development: From Concept to Cash, by Mary Poppendieck and Tom Poppendieck
Further reading: